在這個章節中,我們將學習如何使用PyTorch來訓練一個簡單的機器學習模型。PyTorch是一個強大且靈活的深度學習框架,廣泛應用於研究和工業界。通過這個教程,你將學會如何安裝PyTorch、準備數據、構建和訓練模型,並評估模型的性能。
如果沒有要用自己的電腦跑 Model 可以跳過 Setting 的步驟。
首先,我們需要確認是否已經進入自己的環境:
$ conda activate test
接著我們需要安裝PyTorch。你可以使用以下命令來安裝PyTorch:
nvidia-smi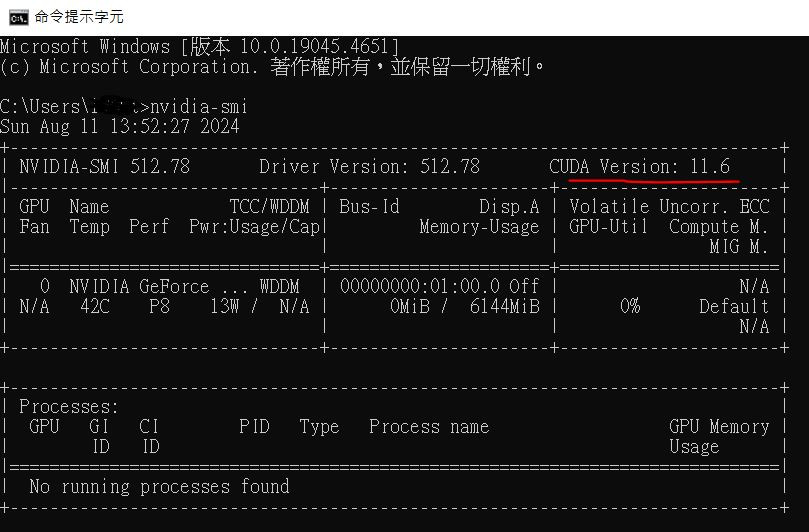
如果是
CUDA 11就選CUDA 11.X,後面小數點不一樣沒關係
$ pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
下載以下Dataset
https://www.kaggle.com/competitions/dogs-vs-cats-redux-kernels-edition
根據前幾日準備好的程式,套用進去。
train_dir = '/kaggle/working/dataset/train_set/'
test_dir = '/kaggle/working/dataset/test_set/'
class dataset(torch.utils.data.Dataset):
def __init__(self, file_path, transform = None):
self.file_path = file_path
self.file_list = glob.glob(file_path+'*/*.jpg')
self.transform = transform
def __len__(self):
return len(self.file_list)
def __getitem__(self,idx):
img_path = self.file_list[idx]
image = Image.open(img_path)
if self.transform:
img = self.transform(image)
label = img_path.split('/')[-1].split('.')[0]
if label == 'dog':
label = 1
elif label == 'cat':
label = 0
return img, label
train_dataset = dataset(train_dir, train_transform)
test_dataset = dataset(test_dir, transform)
train_transform可以自己新增方法。
train_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean = [0.4883, 0.4551, 0.4170], std = [0.2276, 0.2230, 0.2233]),
transforms.Resize([64, 64])
])
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean = [0.4883, 0.4551, 0.4170], std = [0.2276, 0.2230, 0.2233]),
transforms.Resize([64, 64])
])
接下來,我們需要構建一個簡單的神經網絡模型。
這邊我們直接使用torchvision裡面內建的models,使用他的預訓練權重 pretrained=True 。
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torchvision.models as models
# 加載預訓練的 ResNet18 模型
model = models.resnet18(pretrained=True)
# 調整最後一層
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, 2)
設置損失函數和優化器,然後進行模型訓練。
在訓練模型之前,我們需要定義損失函數和優化器。在這個例子中,我們將使用交叉熵損失函數和Adam優化器:
除了CrossEntropyLoss,也可以自己替換適合的loss 或是 上次有學到的 直接與其他的loss相加
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 訓練循環
for epoch in range(num_epochs):
running_loss = 0.0
for inputs, labels in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch {epoch + 1}, Loss: {running_loss / len(trainloader)}')
訓練完成後,我們需要評估模型的性能。以下代碼展示了如何在測試數據集上評估模型:
使用驗證集評估模型的性能,計算準確率等指標。
Accuracy之外也可以自己採用別的方法去評估整體模型。
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in val_loader:
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print(f'Accuracy: {accuracy}%')
torch.save(model,'model.pth')
使用訓練好的模型對新圖像進行預測。
這邊是用一張圖片的例子去做示範。
def predict_image(image):
image = transform(image).unsqueeze(0)
outputs = model(image)
_, predicted = torch.max(outputs.data, 1)
return 'Cat' if predicted.item() == 0 else 'Dog'
這些步驟涵蓋了從資料準備到模型訓練和預測的完整過程。
ResNet18 的優點在於其較少的參數量和較快的收斂速度,非常適合這類圖像分類任務。
可以嘗試自己寫一份可以運行的紀錄/看時間的code。
通過這個教程,我們學習了如何使用PyTorch來訓練一個簡單的神經網絡模型。我們從安裝PyTorch開始,準備數據,構建模型,定義損失函數和優化器,訓練模型,並最終評估模型的性能。希望這個教程能幫助你理解和掌握PyTorch的基本使用方法,並為你進一步學習和探索AI技術打下基礎。